
AI, undoubtedly, gives you a competitive edge - whether it’s in your daily life or professional work. But most business leaders don’t understand how LLMs (Large Language Models) work. Being a business leader in an enterprise company, understanding these models helps you make informed choices.
No, you don’t need to be a data scientist to make informed AI decisions. But a foundational understanding of how LLMs are trained will help you evaluate AI vendors, allocate budgets wisely, and ensure AI aligns with your business goals.
So, we have decided to break down the essentials clearly without going technically deep. You’ll learn:
- LLM fundamentals
- How are LLMs trained - step-by-step process.
- Key business considerations like cost, compliance, and scalability.
- How does fine-tuning differ from pre-training?
- Practical insights to help you choose the right language model for your business.
When you’re through with this article, you will understand how to train your own model, fine-tune an existing one, or leverage a pre-trained solution.
Let’s get started.
What is an LLM?
First, let’s try and understand what LLM means. Large Language Models are advanced AI models designed to generate human-like text. They power everything from chatbots to automated content creation and intelligent search systems. But there’s a resource-intensive training process behind their impressive responses.
And how large? "Large" can refer either to the number of parameters in the model, or the number of words in the dataset. Right now we have models that have more than a trillion parameters.
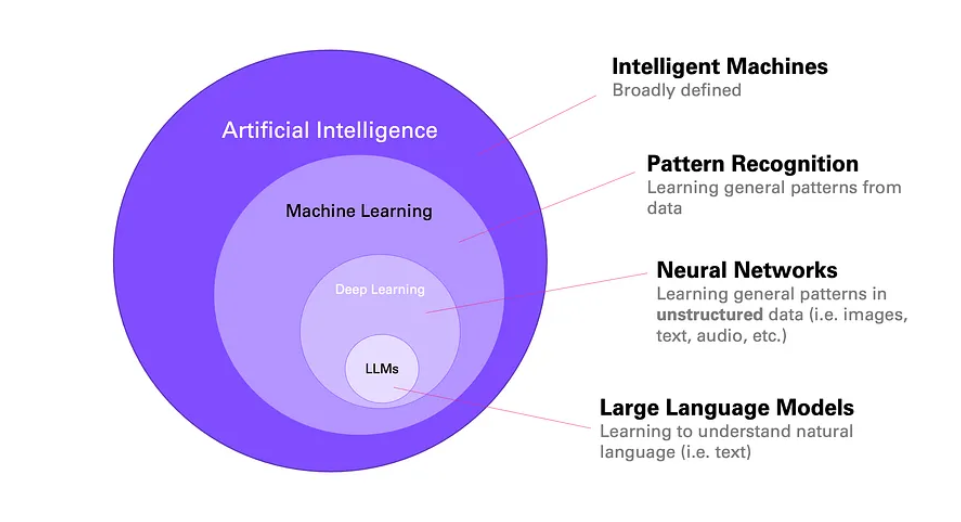
AI is a broad term. There are many moving parts that work together to build those systems that we see today. Language models use machine learning (ML), specifically - deep learning. These models can train themselves and comprehend human language. And to understand how LLMs work knowing certain basic concepts would help.
Architecture, training process, principles that enable LLMs to recognize patterns, etc. are a couple of them. They may sound too complicated to understand but these underlying principles are very intuitive.
How do these language models work? Let’s see through a simple example.
- First, you give a prompt: ‘’Summarize the report”.
- This prompt is then broken down into pieces (tokens) by the model.
- It runs these tokens through layers of a neural network to figure out context and meaning.
- One by one, it guesses the next word based on patterns it has learned.
- It keeps generating words until a full, readable answer is formed.
Of course, this is a very simple explanation. The actual process is quite complex with different layers and steps. At a basic level, this is how language models work.
Fundamentals of Language Models: How do they work
Architecture
The LLMs use Transformer architecture. This helps a model to process and understand sequential data such as text. Transformer is a neural network architecture that uses ‘self attention mechanism’ to model relationships between the words and generate the next word.
Simply put, the model:
- First reads the sentence and creates a structured representation of its meaning.
- Then, it builds the translated sentence word by word, using the original meaning as a guide.
It considers the full context of the sentence, adjusting each word’s meaning based on the others. This allows for more accurate and natural translations.
The figure below explains the process neatly.

Source: Google Research
How are LLMs Trained?
The following are the usual training phases for LLMs. It involves data collection,training the model on the collected data and then improving the model.
Pre-training
This is the first training phase where the model is exposed to huge amounts of data. Here it learns language patterns by analyzing data from books, articles, websites, and other sources. This exposure helps the model understand syntax, grammar, and context but doesn’t make it industry or task-specific.
Even though the quantity of input is high, output isn’t very impressive. And, it is not supposed to be either. At this stage, the language structure isn’t aligned with what humans want to do. Because it’s not following instructions. Here, it’s just trying to complete the given input correctly And, the result is basically a foundation model.
Fine-tuning
Now, it’s time to get the model to follow instructions. The foundation model you got from the previous phase undergoes supervised fine tuning. As the name suggests, in this phase the model is trained on fine tuning its abilities for specific tasks. So, the model will be trained on either high quality domain specific or task specific data.
The data will include prompts and their responses. And, this way the language model learns to generate responses according to the prompts given to it.
RLHF
Reinforcement Learning from Human Feedback (RLHF) is the last phase of the training process that some LLMs like ChatGPT go through. This training phase is necessary to help the model reach a human-like performance.
The combination of reinforcement learning and language modeling is promising and can lead to some massive improvements over the LLMs we currently have. You see, ChatGPT–the most popular LLM– uses RLHF training to make it think and work like a human. And, the GPT stands for Generative, Pre-trained, and Transformer.

Source: Andreas Stöffelbauer
Related read: The Difference Between Training Data vs. Test Data in Machine Learning
Examples of Large Language Models
Now that you understand how LLMs are trained, let’s look at some language model examples. ChatGPT is the most popular one, undoubtedly. It is a generative AI chatbot from OpenAI, which was launched in 2022 and since then has been competing with every new model. However, there are many advanced LLMs available in the market today. Some of them are mentioned below.
GPT-4
This is the largest model in OpenAI’s GPT series. It is a transformer based model and was released in 2023. Its parameter count is a whopping 170T! And, this massive dataset is what makes it stand out among other LLMs. It can not only easily generate text but also allows users to specify tone, voice, etc.
Claude 3.5 Sonnet
This is the most recent version of the Claude LLM. Claude has 3 tiers - Opus, Sonnet and Haiku - sonnet being a cost effective solution for generative tasks. It’s suitable for app development because of its broad programming capabilities. The model is accessible via the Claude iOS app, Claude.ai, and through an API.
BERT
BERT - Bidirectional Encoder Representations from Transformers - is an open source LLM launched in 2018 by Google. It was one of the first LLMs introduced, which in a way started the LLM revolution. There are many BERT models available and still used by many companies for their specific use cases.
DeepSeek- R1
This is an open source model by DeepSeek. It handles tasks like mathematical problem solving, complex reasoning, etc. It uses the RLHF training (mentioned earlier) to train and refine its complex tasks handling ability.
These are just a few examples of existing LLMs. These LLMs are mostly trained similarly- with parameters being the biggest differentiator. Some models are fed millions and some billions. This depends on who’s the developer of the model, cost, scalability, etc. plus other factors.
What are the disadvantages of LLMs?
Even though these models are impressive, not everything is hunky dory. A major pitfall is inheritance. It means they can inherit and mirror those exact flaws that the dataset, they were trained on, had.
The biases and the inaccuracy present in the data will be seen in the outputs resulting in discriminatory language, fake news, misinformation, etc. This raises ethical concerns about using LLMs for content generation. It can also raise legal and privacy concerns, especially when it comes to issues like IP (intellectual property), disclosure of sensitive information, plagiarism, etc.
So, developers know that these models hallucinate. LLMs, sometimes, perceive patterns that either don’t exist or just can’t be realized by humans. And, provide inaccurate or nonsensical outputs, as a result. This phenomenon - AI hallucinations - is real.
To prevent these pitfalls, the developers ensure that the training data quality and relevance is high. They try to train the model on a diverse dataset to prevent depending too much on only one.
Real World Application of Language Models in Enterprises
LLMs play an important role in shaping up the latest tech in artificial intelligence. These models comprehend and generate human-like text brilliantly. This helps in more sophisticated interactions between machines and people. Which is why LLMs are the backbone of several real world applications.
Airbnb

Airbnb, founded in 2008, is one of the big players in the travel industry. As of September 2024, the company has recorded 2B+ total guest arrivals, and 5M+ hosts on the platform. Airbnb has fueled this growth by utilizing machine learning to solve a complex problem - matching hosts and guests.
The company integrated LLM to assist in personalized search recommendations for accommodations and optimize pricing for hosts. Through which, it improved the user experience and drove more guest bookings.
Airbnb used the data it generated to feed into the model to
- Come up with a better prediction of which listings to show customers first.
- Predict maximum revenue per night for listings.
Hence, the company successfully implemented the results of the model and grew the way it did.
Amtrak

Amtrak, a US-based passenger railroad service, faced a major challenge. They saw a huge influx of daily calls with questions about train schedules, etc. Approximately - 84000 daily calls!
So, after much planning, Amtrak introduced Julie - AI powered customer service representative. Julie is ready 24/7 to answer queries, book tickets, and even check train status for the daily callers.
Since her introduction, the company has seen a 25% increase in bookings and an unbelievable 30% in customer service cost saving. Not only this, Amtrak saw an increased customer satisfaction by 53% over the old system. According to the company, Julie completes more calls per day than one human representative handles per year.
Amtrak’s Julie is the perfect example of chatbots (LLM) improving ROI for customer service in enterprises.
Uber

Uber encountered a problem. For mobile testing, the company noticed that its engineers were investing 30–40% of their time on maintenance. And, this increased maintenance costs made it harder for Uber to efficiently scale testing.
As a solution, they developed DragonCrawl, a system that utilizes LLMs to perform mobile tests with human-like intuition. With the system in their workflows, the company saw saved developer hours and reduced test maintenance costs.
Uber thought of mobile testing as a language generation problem. Mobile tests are just sequences of steps, but things can change and cause issues along the way. To overcome these and complete a test, the system needed clear context and goals.
Which is why they used LLM for resolving this challenge. And, they succeeded.
How to Choose the Right LLM for your Business
How to decide which LLM to use? There isn’t one model that you can pick and use for all your requirements. You have to start by drilling into your business requirements. Use this information to guide you to make informed decisions.
Other key things to consider are:
- Your requirements - Identify the problem you need to solve. A clear understanding of the task at hand ensures the chosen model aligns with your task goals and business objectives.
- Cost - Evaluate the computational speed and the cost of running the model for your use case. For example, chatbots need faster models but these LLMs can be quite expensive.
- Quality of your training data - How LLMs are trained directly impacts the quality of the output the model gives. So, ensure that you
- Scalability - Select a model that can scale as your business grows without breaking the system.
- Ease of use - Choose models that are easy to deploy. If your team doesn’t have the required AI expertise, you can opt for platforms that can manage and train your data. You can, alternatively, check for LLMs that offer APIs that you can use readily.
- Ethics and safety - The more sensitive data you want to train the model on, the higher is the risk of biased or inaccurate outputs. Select the LLM that allows you to understand how it generates results.
You can’t just pick one model and be done with it. You would have to test multiple models. When you experiment with different models you get to know which one works best for your use case.
Final thoughts
LLMs have the potential to redefine how businesses operate. They offer smarter automation, data-driven insights, and personalized customer experiences. LLMs will continue to evolve, so the businesses leveraging them will stay ahead of the curve.
Integrating LLMs into your business operations doesn’t have to be complicated. Zams is the AI command center for sales. Connect your stack, ask in plain English, and get 20+ hours back every week.


.png)
.png)



